
If you are a CTO at a hosting company with less than 50 employees, you have likely witnessed this paradox:
- Cloud bills stabilized
- Storage pricing improved
- ARM instances delivered better cost-performance
- Bandwidth became competitive
Yet your Earnings Before Interest, Taxes, Depreciation, and Amortisation (EBITDA) dropped from 25-30% to sub-15%.
Here’s the uncomfortable truth: Infrastructure didn’t get more expensive. Your operations did.
Infrastructure Is Now a Commodity
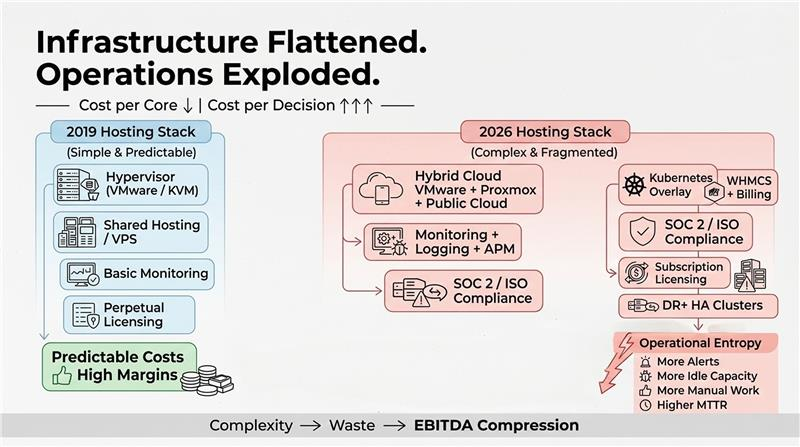
Five years ago, compute pricing defined hosting margins. Today, that game is over.
Savings Plans and Reserved Instances normalized cloud spend. Object storage tiers improved unit economics.
But while infrastructure costs flattened, operational complexity exploded:
- Hybrid VMware, Proxmox, or colocation + public cloud architectures
- Kubernetes layered onto legacy VPS, cPanel, and shared hosting stacks
- Tool sprawl across monitoring, logging, ticketing, and billing systems (Web Host Manager Complete Solution (WHMCS), custom scripts, etc.)
- Subscription-based licensing shifts
- SOC 2 and ISO audit pressure
The problem isn’t cost per core anymore. It’s operational entropy: the hidden friction bleeding margin from every layer of your stack.
VMware (or Proxmox) Clusters: Predictable Spend, Hidden Waste
VMware licensing shifted towards subscription bundles and strict core enforcement.
Most mid-sized hosting environments now face this reality:
Overprovisioning clusters by 25-40%
Maintaining idle HA and DR capacity “just in case”
Reserving compute for spike scenarios that rarely materialize
Even if you are running Proxmox or bare-metal nodes, the pattern is similar: capacity reserved to prevent noisy neighbor complaints, CPU steal issues, and peak-season ticket storms.
Do the math: If your virtualization stack costs $25K/month and 30% sits idle, that’s ~$90K/year in inefficiency.
Not from pricing changes. From governance gaps.
The hardware is fine. The allocation discipline isn’t.
Kubernetes Without SRE Depth = Margin Leakage
Kubernetes accelerated deployment velocity. But in mid-sized hosting firms, it often runs without full Site Reliability Engineering (SRE) discipline:
CPU/memory requests set conservatively high
HPA misconfigurations that trigger unnecessary scaling
No workload-level cost visibility
Alert noise from Prometheus/Grafana drowning signal in static
Manual patch cycles consuming engineering time
If your container resource over-allocation sits at 40% (common in risk-averse setups), the math is brutal:
On $50K/month cloud spend → $240K/year wasted.
That flows directly to EBITDA compression, not because Kubernetes is expensive, but because operational rigor didn’t scale with adoption.
Quick Margin Health Check
How many apply to you?
☐ Mean Time to Repair (MTTR) exceeds 1 hour
☐ More than 50 alerts per engineer daily
☐ Overprovisioned by 30%+
☐ Paying for unused monitoring tools
☐ Engineers doing L1 tickets
☐ Founder or senior architect still in the on-call rotation
☐ SLA credits issued last quarter
☐ Repeated “CPU steal” or noisy neighbor complaints during peak season
Score:
0–2 → Healthy ops
3–4 → Margin leak
5+ → EBITDA erosion zone
If you scored 3 or higher, your operations layer is actively compressing profitability. The good news? This is fixable without rearchitecting your entire stack.
See how Nuventure’s Managed Services can recover hidden margin →
Downtime Is the Real Multiplier
According to Uptime Institute, over 60% of outages exceed $100,000 in impact.
For a $5M hosting business targeting 25% EBITDA ($1.25M), three major incidents at $60K each = $180K in direct loss.
That alone reduces EBITDA by 14%.
And that excludes the downstream damage:
Customer churn and contract non-renewals
Sales friction from prospects asking about your last RFO
Slack war rooms during outages with engineers scrambling
Engineering burnout from 2AM escalations
Brand erosion in competitive RFPs
MTTR is now a financial metric, not just a technical one. Every minute of downtime has a P&L line item attached.
The Math Most CTOs Don’t Model
Typical 25-person hosting firm:
Revenue: $5,000,000
Target EBITDA: $1,250,000 (25%)
Hidden operational drag:
- Downtime incidents: $180K
- VMware/cluster inefficiency: $90K
- Kubernetes waste: $240K
- Tool sprawl subscriptions: $80K
- Burnout-driven turnover: $120K
- Total erosion: ~$710K
- Actual EBITDA after drag: ~$540K (≈11%)
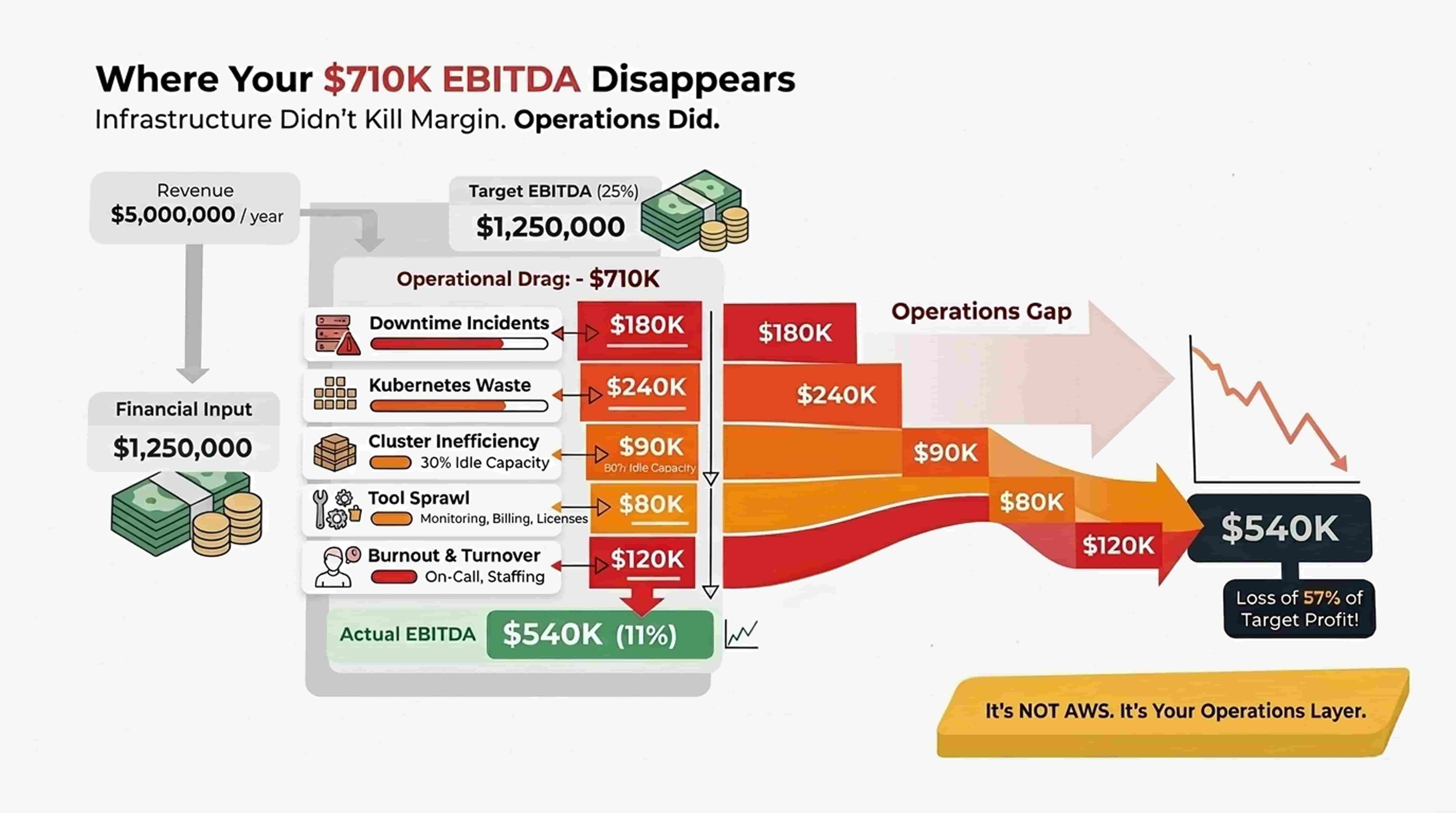
Infrastructure didn’t kill margin. Operational immaturity did.
Why Fixed NOC Models Are Breaking
Most 10-50 employee hosting firms run a traditional ops structure:
- 4-6 operations engineers
- Multiple monitoring tools stitched together
- Reactive incident response workflows
- Manual scaling and patching routines
- L3 engineers getting paged for L1 alerts
That’s $400K+ in fixed payroll before tooling costs.
But revenue fluctuates seasonally: Q4 spikes, Q1 dips.
Fixed operations + variable demand = margin volatility.
Modern hosting economics require variable operations that scale with workload, not headcount.
The 2026 Hosting Differentiator
Differentiation won’t come from:
- Lowest VPS price
- Most cores per dollar
- Cheapest bandwidth
It will come from:
- <30-minute MTTR across severity tiers
- 99.99% SLA reliability with automated failover
- Predictable cluster utilization through dynamic right-sizing
- Workload-level cost visibility
- Automated compliance readiness for SOC 2 and ISO audits
- Infrastructure is table stakes. Operational maturity is the EBITDA lever.
Stop Leaving $700K on the Table
You wouldn’t tolerate 30% waste in your compute budget. Why accept it in your operations layer?
If your engineers are drowning in alert noise, your clusters are overprovisioned, and your MTTR is eroding customer trust, you are not running a hosting business.
You are subsidizing operational inefficiency.
Recover half that $710K in annual operational drag, and you are back at 20%+ EBITDA.
Without adding a single customer.
See how Nuventure turns ops from a cost center into a margin recovery engine →
Or keep doing what you are doing, and watch your competitors figure it out first.



